Fraud is a major challenge in any financial system, not least of which is that of taxation. Typically, tax fraud has been addressed by having teams of fraud experts auditing cases individually. Given that the volume of tax information far exceeds what fraud experts can reasonably handle through their limited resources, the process usually starts by filtering these cases - by having the experts identifying combinations of tax declaration features which might be deemed to be potentially suspicious such as 'Identify all company directors who have declared less than €3,000 income in any three years of assessment'.
After identifying such rules, they would be passed on to the IT team, where software developers would interpret and manually translate them into database queries to fetch the relevant records which would then be passed on to the fraud experts for analysis. The fraud expert would then assess whether the rule requires modification or refinement (for example, by limiting the query to directors who declared low income in three consecutive years of assessment, or by increasing the limit from €3,000 to €4,000). This might be required if the rule does not quite work as expected or if it is capturing too many or too few instances - and the process of rule refinement would typically be iterated various times. This process is shown in Fig. 1.
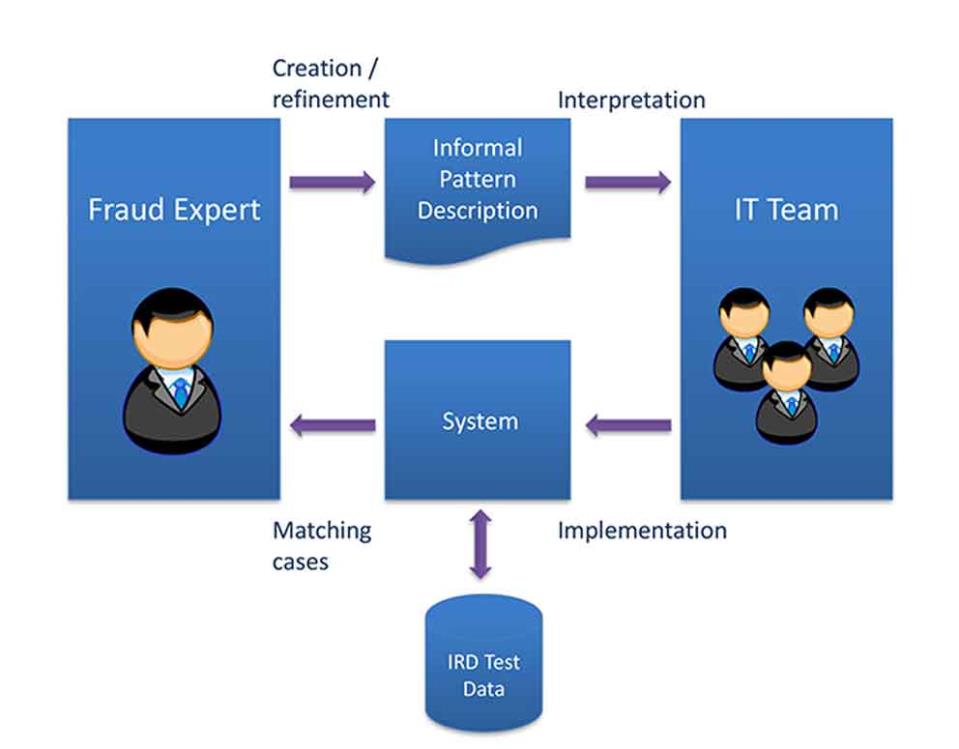
Figure 1. Current iterated approach to tax fraud detection
In an ideal setting, this process is an effective one. However, in practice, there may be several reasons why the fraud expert does not get the expected kind or number of cases for the specified rule: from the developer's side, either by misinterpreting part of the rule or the terms used (for example, implementing the query using the profit instead of the turn-over of a company), or due to bugs in the query implementation; to the fraud expert's side, by designing a rule which is not effective enough or at all. The fraud expert might end up investing substantial time and energy trying to refine the rule to make it work better only to discover at a later stage that the results were skewed due to a software bug. The iterative nature of the process, and the fact that each iteration requires substantial time and effort results in a process which might drag out over time, with the danger of the fraud expert stopping when results are good-enough, rather than continue honing the rules to extract the maximum benefit possible.
The ideal way of addressing this is either to have automated means of deriving fraud rules (thus partly doing away with the fraud expert), or to allow the fraud expert to write the queries directly (thus doing away with the IT team). Much work has been done on the former using artificial intelligence and machine learning techniques, however, yielding limited success - with far lower accuracy than what a human fraud expert can achieve. With the latter solution, it is clearly not feasible to expect a fraud expert to be trained to be able to script database queries directly in a programming or scripting language.
A more agile approach to fraud detection
In our system we have adopted controlled natural languages (CNLs) to enable fraud experts to write rules without having to master a technical language. Controlled natural languages are the combination and balance of two language features:
1. The language is "controlled", in the sense that it is limited and focused on a specific domain, reducing the size of the vocabulary and grammar of the language. While its complexity is reduced, it can still be expressive enough to define needed phrases for its domain.
2. The language also has a "natural" feel to it - as in human languages such as English and Maltese, having morphological rules (e.g. singular and plural, and conjugation).
The natural aspect of these languages has been shown to make them more readable by non-technical people, but also, if well designed, an effective way in which such non-technical persons can express requests or describe scenarios. On the other hand, the controlled aspect of these languages means that they can also be unambiguously processed by a computer.
We have been looking into the use of a controlled natural language to support fraud experts to write and assess rules on tax payers' data. The framework, shown in Figure 2, allows the fraud expert to write rules in our tax-fraud-specific controlled natural language to filter the Inland Revenue Department's (IRD) database of tax return information.
Furthermore, it was noted that due to the size of the IRD database, feedback from a rule can take up to a few minutes (depending on the complexity of the rule) to obtain feedback, which slows down the rule experimentation and discovery process. In order to address this, we have built a rules playground - a smaller collection of sample data which can be used by a tax fraud expert to rapidly experiment with new rules. Once the expert is confident with a new rule, it may be used on the whole IRD database, which is continuously fed with new live data.
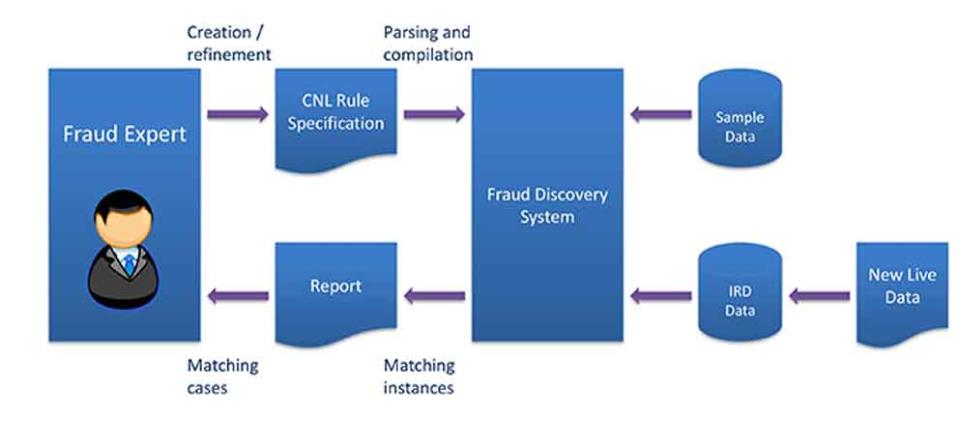
Figure 2: A controlled natural language approach to support tax-fraud discovery
Examples of rules written in the fraud specification language are the following:
- Load the ID, year of assessment and age where for any 3 sequential years from 2009 onwards, an individual of age more than 30 declared a total income less than €3,000.
- Load the ID, year of assessment, total income, total expenses and total deductions where for any year, a taxpayer declared a total income less then total expenses or a total income less than total deductions.
- Load the ID where for any year, an individual declared the total income for the current year to be less than the average income for the previous three years.
The end result is a language in which a fraud expert can define query rules, using tax related concepts (such as "profit" and "tax rebate"), and means of combining information from the database (for example the "average income for the previous three years"). The language allows the specification of tax fraud patterns through four types of constructs:
1. Taxpayer filters - limit which taxpayers should be considered for evaluation, for example "individuals of age more than 30".
2. Tax-return conditions - allows checks to be made on information available from tax return forms, for example "total income is less than €3,000".
3. Time-based reasoning - the language includes a notion of time in order to limit queries to certain years, or to check the duration of certain properties. For example, "total income is less than €3,000 for 4 sequential years", and "total income is less than €3,000 for any 3 years between 1999 and 2014".
4. Reporting - taxpayers which pass through the filters are compiled into a report. The language allows for the specification of what information is relevant for the report, for example ID number, years of assessment, etc.
Our system parses the rules written using this controlled natural language and uses them to process the back end IRD database. The matched cases are returned to the fraud expert in a report, configurable by the fraud expert within the language itself. The final result would allow the fraud expert to refine the rule in a "what-if" manner where the feedback would indicate the accuracy of the rule.
What do fraud experts think of the system?
To assess the quality of the proposed framework, fraud experts from the Tax Audits and Tax Compliance Unit Departments as well as accountants from the private sector have been interviewed after having used the domain specification language and obtained fraud case results.
In the first exercise we attempted to get feedback on how easy it is for fraud experts to use the language with little or no help. Three out of every four participants were able to understand all the rules (including considerably complex ones) and all participants managed to express a rule of their choice through the language.
Next, we evaluated whether the language is able to express any rule the fraud experts would want to express. Baring a number of data fields which can easily be added to the language, our language passed the test.
Finally, we measured the performance of the tool by trying it on the sample data set of 53,000 tax return forms, and the full data set of 3.2 million records. In the case of the former, the system took four seconds to complete the job, while in the latter the results were ready in 3 minutes. Given these times, the turnaround time for experts to experiment with different rules would be improved by several orders of magnitude.
We hope to collaborate further with the Tax Audits and Tax Compliance Unit Departments to continue improving our language and tool both in terms of usability and efficiency, with the ultimate aim of facilitating a task of national importance with great potential.
This article highlights the work carried out for a Master's Degree thesis with the University of Malta, in the area of controlled natural languages and how they can be used to support fraud detection. The work was carried out by Mr Aaron Calafato, supervised by Professor Gordon Pace and Dr Christian Colombo supported by the University of Malta Research Fund, and was done in collaboration with the Inland Revenue Department.